
python学习(08) - 优化器定义及学习率的调整
在实验过程中,学习率(lr)的选取非常重要,因为:
- lr过小,导致loss降低缓慢;
- lr过大,导致loss无法下降到最优值,在最优值左右横跳。
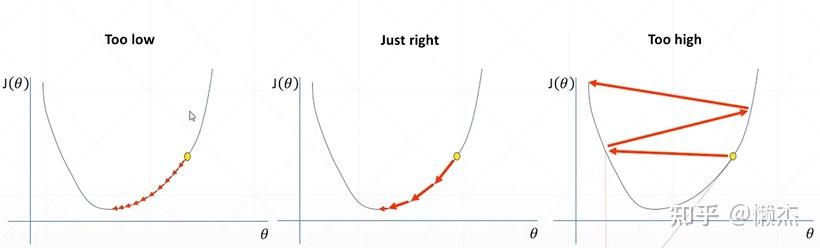
图引自:使用Pytorch实现学习率衰减/降低(learning rate decay)
因此,有这么一个思路:能否随着训练次数的增加而逐渐调整学习率呢?
学习率的选择:
https://www.freesion.com/article/33411216091/一个确定学习率的思路
首先设置一个十分小的学习率,并在每个epoch之后增大学习率,并记录好每个epoch的loss或acc。迭代的epoch越多,那么被检验的学习率就越多,最后将不同学习率对应的loss或acc进行对比,从而确定学习率。
torch.optim 是一个实现各种优化算法的包。
要使用torch.optim,必须构造一个optimizer对象,该对象将保持当前状态,并将根据计算出的梯度更新参数。
要构造一个optimizer,我们必须给它一个包含要优化的参数(所有参数应该是Variable类型)的迭代器。然后,可以指定特定于optimizer的选项,如学习率、权重衰减等。
例如:
optimizer=torch.optim.SGD(model.parameters(), lr=0.01, momentum=0.9)
optimizer=torch.optim.Adam(filter(lambda p: p.requires_grad, model.parameters()), lr=0.05)optimizer也支持指定每个参数的选项。要做到这一点,不是传递一个Variable的迭代,而是传递一个可迭代的dict。每个变量都将定义一个单独的parameter group,并且应该包含一个 params 键,包含一个属于它的参数列表。其他键应该与优化器接受的关键字参数匹配,并将用作该组的优化选项。
我们仍然可以将选项作为关键字参数传递。它们将作为默认值,在没有覆盖它们的组中使用。如果只希望改变单个选项,同时保持参数组之间所有其他选项的一致性时,这种方法非常有用。
例如,想要指定每层的学习速度时:
optim.SGD([
{'params': model.base.parameters()},
{'params': model.classifier.parameters(), 'lr': 1e-3}
], lr=1e-2, momentum=0.9)则:model.base 的参数将使用默认的学习率1e-2,model.classifier 的参数将使用学习率1e-3,并且所有参数的momentum为0.9。
所有的优化器都实现了一个 step()方法来更新参数:optimizer.step()。当使用如backward()等方法计算出梯度后,就可以调用step()更新参数。
例如:
for input, target in dataset:
optimizer.zero_grad()
output=model(input)
loss=loss_fn(output, target)
loss.backward()
optimizer.step()参数:
- params(iterable) - 可迭代的torch.Tensor或dict,用来指定需要优化的张量。
- defaults(dict) - dict,包含优化选项的默认值(当参数组没有指定它们时生效)。
方法:
- Optimizer.add_param_group - 添加一个参数组到优化器的参数组
- Optimizer.load_state_dict - 加载优化器状态
- Optimizer.state_dict - 以字典形式返回优化器的状态
- Optimizer.step - 执行单个优化步骤(参数更新)
- Optimizer.zero_grad - 所有需优化张量的梯度清零
优化算法:
- Adadelta - 自适应学习率方法
- params (iterable) – 要优化的参数或定义参数组的字典
- rho (float, optional) – 用于计算平方梯度运行平均值的系数(default: 0.9)
- eps (float, optional) – 添加到分母以提高数值稳定性的项(default: 1e-6)
- lr (float, optional) – 学习率(default: 1.0)
- weight_decay (float, optional) – 权重衰减(L2 惩罚) (default: 0)
- Adagrad - 在线学习和随机优化的自适应次梯度方法
- params (iterable) – 要优化的参数或定义参数组的字典
- lr (float, optional) – 学习率(default: 1e-2)
- lr_decay (float, optional) – 学习率衰减指数(default: 0)
- weight_decay (float, optional) – 权重衰减(L2 惩罚)(default: 0)
- eps (float, optional) – 添加到分母中以提高数值稳定性的项 (default: 1e-10)
- Adam - 一种随机优化方法
- params (iterable) – 要优化的参数或定义参数组的字典
- lr (float, optional) – 学习率 (default: 1e-3)
- betas (Tuple[float, float], optional) – 用于计算梯度及其平方的运行平均值的系数 (default: (0.9, 0.999))
- eps (float, optional) – 添加到分母以提高数值稳定性的项 (default: 1e-8)
- weight_decay (float, optional) – 权重衰减(L2 惩罚)(default: 0)
- amsgrad (boolean, optional) – 是否使用此算法的AMSGrad变体 (default: False)
- AdamW - 解耦权重衰减正则化的Adam变体
- params (iterable) – 要优化的参数或定义参数组的字典
- lr (float, optional) – 学习率 (default: 1e-3)
- betas (Tuple[float, float], optional) – 用于计算梯度及其平方的运行平均值的系数 (default: (0.9, 0.999))
- eps (float, optional) – 添加到分母以提高数值稳定性的项 (default: 1e-8)
- weight_decay (float, optional) – 权重衰减(L2 惩罚)(default: 1e-2)
- amsgrad (boolean, optional) – 是否使用此算法的AMSGrad变体 (default: False)
- SparseAdam - 适用于稀疏张量的 Adam 算法。在这个变体中,只有在梯度中显示的时刻被更新,并且只有那些梯度的部分被应用到参数中。
- params (iterable) – 要优化的参数或定义参数组的字典
- lr (float, optional) – 学习率 (default: 1e-3)
- betas (Tuple[float, float], optional) – 用于计算梯度及其平方的运行平均值的系数 (default: (0.9, 0.999))
- eps (float, optional) – 添加到分母以提高数值稳定性的项 (default: 1e-8)
- Adamax - 基于无穷范数的Adam变体
- params (iterable) – 要优化的参数或定义参数组的字典
- lr (float, optional) – 学习率 (default: 2e-3)
- betas (Tuple[float, float], optional) – 用于计算梯度及其平方的运行平均值的系数
- eps (float, optional) – 添加到分母以提高数值稳定性的项 (default: 1e-8)
- weight_decay (float, optional) – 权重衰减(L2 惩罚)(default: 0)
- ASGD - 实现平均随机梯度下降
- params (iterable) – 要优化的参数或定义参数组的字典
- lr (float, optional) – 学习率 (default: 1e-2)
- lambd (float, optional) – 衰减项 (default: 1e-4)
- alpha (float, optional) – power for eta update (default: 0.75)
- t0 (float, optional) – 开始求平均值的点 (default: 1e6)
- weight_decay (float, optional) – weight decay (L2 penalty) (default: 0)
- LBFGS - 这个优化器不支持每个参数选项和参数组(只能有一个)。这是一个非常占用内存的优化器
- lr (float) – 学习率 (default: 1)
- max_iter (int) – 每个优化步骤的最大迭代次数(default: 20)
- max_eval (int) – 每个优化步骤的最大函数计算次数(default: max_iter * 1.25).
- tolerance_grad (float) – 一阶最优终止公差(default: 1e-5).
- tolerance_change (float) – 函数值/参数变化的终止容差(default: 1e-9).
- history_size (int) – 更新历史大小 (default: 100).
- line_search_fn (str) – either ‘strong_wolfe’ or None (default: None).
- RMSprop - 在添加epsilon之前取梯度平均值的平方根
- params (iterable) – 要优化的参数或定义参数组的字典
- lr (float, optional) – 学习率 (default: 1e-2)
- momentum (float, optional) – 动量系数 (default: 0)
- alpha (float, optional) – 平滑常数 (default: 0.99)
- eps (float, optional) – 增加到分母的项,以提高数值稳定性 (default: 1e-8)
- centered (bool, optional) – 如果为真,计算为中心的 RMSProp,梯度将通过其方差的估计进行归一化
- weight_decay (float, optional) – weight decay (L2 penalty) (default: 0)
- Rprop - 实现弹性反向传播算法
- params (iterable) – 要优化的参数或定义参数组的字典
- lr (float, optional) – 学习率 (default: 1e-2)
- etas (Tuple[float, float], optional) – 一对(etaminus, etaplis),它们是乘增和减因子(默认值:(0.5,1.2)) (default: (0.5, 1.2))
- step_sizes (Tuple[float, float], optional) – 允许的最小步长和最大步长对(default: (1e-6, 50))
- SGD - 实现随机梯度下降(可选带有动量
- params (iterable) – 要优化的参数或定义参数组的字典
- lr (float) – 学习率
- momentum (float, optional) – 动量系数 (default: 0)
- weight_decay (float, optional) – 权重衰减(L2 penalty) (default: 0)
- dampening (float, optional) – 动量衰减 (default: 0)
- nesterov (bool, optional) – 启用nesterov动量 (default: False)
torch.optim.lr_scheduler提供了几种基于 epochs 数量调整学习速率的方法。
学习率调整应该在优化器更新之后应用,例如:
model=[Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer=SGD(model, 0.1)
scheduler=ExponentialLR(optimizer, gamma=0.9)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output=model(input)
loss=loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler.step()大多数学习率调整器可以被称为背靠背调整器(也称为链式调整器)。结果是,每个调度器都会根据前一个调度器获得的学习速率逐个应用。
例如:
model=[Parameter(torch.randn(2, 2, requires_grad=True))]
optimizer=SGD(model, 0.1)
scheduler1=ExponentialLR(optimizer, gamma=0.9)
scheduler2=MultiStepLR(optimizer, milestones=[30,80], gamma=0.1)
for epoch in range(20):
for input, target in dataset:
optimizer.zero_grad()
output=model(input)
loss=loss_fn(output, target)
loss.backward()
optimizer.step()
scheduler1.step()
scheduler2.step()用以下模板来引用调整器算法:
scheduler=...
for epoch in range(100):
train(...)
validate(...)
scheduler.step()- lr_scheduler.LambdaLR - 将每个参数组的学习速率设置为给定函数的初始lr倍。当last_epoch=-1时,将初始lr设置为lr。
- optimizer (Optimizer) – 封装好的优化器
- lr_lambda (function or list) – 给定一个整数参数历元计算一个乘法因子的函数,或者给定一个乘法因子的函数列表,对于 optimizer.param_groups 中的每个组都是一个
- last_epoch (int) – last epoch的索引. Default: -1.
- verbose (bool) – 如果为 True,则为每次更新打印一条消息到 stdout. Default: False.
>>> # Assuming optimizer has two groups.
>>> lambda1=lambda epoch: epoch // 30
>>> lambda2=lambda epoch: 0.95 ** epoch
>>> scheduler=LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()- lr_scheduler.MultiplicativeLR - 将每个参数组的学习率乘以指定函数中给定的系数。当last_epoch=-1时,将初始lr设置为lr。
- optimizer (Optimizer) – 封装好的优化器
- lr_lambda (function or list) – 给定一个整数参数历元计算一个乘法因子的函数,或者给定一个乘法因子的函数列表,对于 optimizer.param_groups 中的每个组都是一个
- last_epoch (int) – last epoch的索引. Default: -1.
- verbose (bool) – 如果为 True,则为每次更新打印一条消息到 stdout. Default: False
>>> lmbda=lambda epoch: 0.95
>>> scheduler=MultiplicativeLR(optimizer, lr_lambda=lmbda)
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()- lr_scheduler.StepLR - 在每一step_size epochs,通过gamma衰减每个参数组的学习率。请注意,这种衰减可能与来自此调度程序外部的学习速率的其他更改同时发生。当last_epoch=-1时,将初始lr设置为lr。
- optimizer (Optimizer) – 封装好的优化器
- step_size (int) -学习率衰减的周期
- lgamma(float)-学习率衰减的乘法因子。默认值:0.1
- last_epoch (int) – last epoch的索引. Default: -1.
- verbose (bool) – 如果为 True,则为每次更新打印一条消息到 stdout. Default: False
>>> # Assuming optimizer uses lr=0.05 for all groups
>>> # lr=0.05 if epoch < 30
>>> # lr=0.005 if 30 <=epoch < 60
>>> # lr=0.0005 if 60 <=epoch < 90
>>> # ...
>>> scheduler=StepLR(optimizer, step_size=30, gamma=0.1)
>>> for epoch in range(100):
>>> train(...)
>>> validate(...)
>>> scheduler.step()- lr_scheduler.MultiStepLR - 一旦epoch数量达到一定程度,则通过gamma衰减每个参数组的学习速率。请注意,这种衰减可能与来自此调度程序外部的学习速率的其他更改同时发生。当last_epoch=-1时,将初始lr设置为lr。
- optimizer (Optimizer) – 封装好的优化器
- milestone(list)-列表的历元索引。必须增加
- gamma(float)-学习率衰减的乘法因子。默认值:0.1
- last_epoch (int) – last epoch的索引. Default: -1.
- verbose (bool) – 如果为 True,则为每次更新打印一条消息到 stdout. Default: False
- lr_scheduler.ExponentialLR - 每个epoch按gamma衰减每个参数组的学习率。当last_epoch=-1时,将初始lr设置为lr。
- optimizer (Optimizer) – 封装好的优化器
- gamma(float)-学习率衰减的乘法因子
- last_epoch (int) – last epoch的索引. Default: -1
- verbose (bool) – 如果为 True,则为每次更新打印一条消息到 stdout. Default: False
- lr_scheduler.CosineAnnealingLR - 实现SGDR的余弦退火部分
- optimizer (Optimizer) – 封装好的优化器
- T_max(int) - 最大迭代次数
- eta_min(float) - 最低学习率。默认值:0
- last_epoch (int) – last epoch的索引. Default: -1
- verbose (bool) – 如果为 True,则为每次更新打印一条消息到 stdout. Default: False
- lr_scheduler.ReduceLROnPlateau - 当一个指标停止改进时,减少学习速度。一旦学习停滞不前,模型通常会从降低2-10倍的学习率中受益。这个调度程序读取一个度量数据,如果对于数个epoch没有任何改进,那么学习率就会降低。
- optimizer (Optimizer) – 封装好的优化器.
- mode (str) – One of min, max. 在min下,当监控数量停止减少时,lr将减少;在max下,当监控数量停止增加时,它将减少。默认值:“min”。Default: ‘min’.
- factor (float) – 使学习速率降低的因子. new_lr=lr * factor. Default: 0.1.
- patience (int) – 没有改善的epoch数,之后学习率将降低。例如,如果patient=2,那么我们将忽略没有任何改善的前两个阶段,并且只有在第三个阶段之后,如果损失仍然没有改善,我们才会降低LR. Default: 10.
- threshold (float) – 度量新的最优值的阈值,只关注重要的更改. Default: 1e-4.
- threshold_mode (str) – One of rel, abs. 在rel模式下,在max模式下dynamic_threshold=best * (1 + threshold)或在min模式下best * (1 - threshold)。在abs模式下,max模式下dynamic_threshold=best + threshold, min模式下best - threshold. Default: ‘rel’.
- cooldown (int) – 减少lr后,在恢复正常操作之前需要等待的epoch数. Default: 0.
- min_lr (float or list) – 标量或标量列表。所有参数组或每组学习率的下限. Default: 0.
- eps (float) – 应用于lr的最小衰减。如果新旧lr之间的差异小于eps,则忽略更新. Default: 1e-8.
- verbose (bool) – 如果为 True,则为每次更新打印一条消息到 stdout. Default: False
- lr_scheduler.CyclicLR
- lr_scheduler.OneCycleLR
- lr_scheduler.CosineAnnealingWarmRestarts
参考文章:
torch.optim.lr_scheduler:调整学习率_qyhaill的博客-CSDN博客_lr_schedulerhttps://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-ratetorch.optim - PyTorch 1.9.0 documentation
https://pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate

